En esta entrada profundizaremos en el modelo de confianza o trust model.
Se comentarán los puntos de partida y se describirán las primeras fases.
Modelo de amenaza
Las redes inalámbricas de sensores, suele estar en zonas abiertas (open área) y por lo tanto tienen que enfrentarse al riesgo de ataques.
Debido a que pueden comunicarse con anónimos adversarios, información maliciosa puede ser aceptada en su sistema a través de ataques como la captura de nodos o la captura de las claves privadas (usadas en la comunicación en la red y capturadas por atacantes activos que se dedican a la escucha).
Objetivos
Debe focalizarse en crear una red fiable que trabaje con normalidad a pesar de que un nodo se vea comprometido.
Sin ningún mecanismo de evaluación, no podemos garantizar que la red de sensores vaya a trabajar correctamente a pesar de que el sistema este empleando un sistema de criptografía de claves.
Para el objetivo de la resistencia o fiabilidad de la red, el modelo propuesto, se centra en la evaluación de credibilidad de cada nodo-sensor y en filtrar toda aquella información inconsistente y fraudulenta de los nodos maliciosos o comprometidos.
Suposiciones
Existen varias suposiciones dentro del modelo:
-
Cada sensor conoce su posición usando un sistema detección de la localización como el GPS (Global Position System).
-
El tiempo está sincronizado en todos los sensores de la red.
-
Los sensores son colocados densamente para poder capturar el mismo evento, redundantemente, por más de un sensor.
-
Los adversarios intentan introducir información maliciosa para crear confusión en el sistema o para hacer que vaya mal.
Diseño: Trust Evaluation Model
El protocolo del modelo se compone de 4 fases:
-
La primera consiste en dividir el área de monitoreo en rejillas lógicas con una identificación única para cada rejilla.
-
En la segunda, cada nodo identifica a sus vecinos de rejilla mediante el protocolo ECHO.
-
En la tercera fase, cada nodo evalúa la fiabilidad de sus nodos vecinos comparando la información procedente de los otros nodos con la suya propia. La información inconsistente, puede ser detectada en esta fase.
-
En la cuarta, los nodos especiales llamados acumuladores (agreggator), reúnen toda la información correspondiente a los nodos de su correspondiente rejilla, la computan y se la envían al nodo sumidero (sink node).
La información maliciosa puede ser excluida en este fase.
Fase 1: Definición de rejillas.
Se deciden cuales van a ser las áreas de monitoreo; donde se van a producir los eventos, y por lo tanto, donde se deben colocar los sensores.
Después dividimos las áreas de monitoreo en rejillas rectangulares lógicas, proporcionales al número de dispositivos sensores que vayamos a colocar.
Definimos el radio r, que acotará el rango que monitoree cada dispositivo sensor. Dependiendo del número de sensores que tengamos, r variará.
Para ilustrarlo ponemos 2 ejemplos en el que se puede comprobar el uso de un único sensor para cubrir toda la zona, y otro en el que existen varios nodos para monitorear la zona especificada.
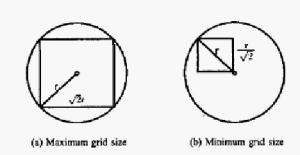
En el primer caso, la rejilla de monitoreo de cada sensor, tendrá que tener el tamaño máximo siendo su área resultante:
En el segundo caso por el contrario, al usarse más de un dispositivo para monitorear toda la zona, el rango a cubrir por cada dispositivo, es menor. El área mínima que tendría que tener sería la siguiente:
Para seleccionar cualquiera de las posibilidades existentes entre estos extremos (los extremos también son seleccionables), hay que considerar los criterios de eficacia y los criterios económicos y seleccionar el que mejor se adecue a nosotros.
Para la explicación del modelo, escogeremos el segundo extremo, donde hay un número mayor de dispositivos, y por lo tanto, mayor información redundante para cotejar la credibilidad de los nodos.
Después de haber dividido las áreas en rejillas lógicas, se les proporciona un identificador único a cada rejilla, que será útil a la hora de identificar a cada sensor.


